
About Me

For information about the Topics in Math course MATH*4060/6181 Winter 2024, scroll down to the paragraph with information below “About me”!
I am an associate professor in the Math & Statistics Department at the University of Guelph working in the area of probability, stochastic processes, and their applications to machine learning. I am also affiliated with the CARE-AI institute and the Vector Institute.
Before Guelph, I was an NSERC postdoctoral fellow at the University of Toronto, with Jeremy Quastel as my supervisor. My old website, http://www.math.toronto.edu/mnica/ has some links to my previous projects.
Before my postdoc at U of T, I was a PhD student at the Courant Institute of Mathematical Sciences in New York under the advisement of Gérard Ben Arous.
Some of my notes and musing are posted at my Obsidian Website https://publish.obsidian.md/nicam/
Email: nicam@uoguelph.ca
Information for MATH*4060/6181 Winter 2024
Title: Introduction to Markov Decision Processes and Reinforcement Learning
Description: Reinforcement learning (RL) is a machine learning paradigm that deals with training autonomous agents to maximize observed rewards. This forms the basis of recent famous AI algorithms that play games like Chess and Go. This course provides a mathematical introduction to the theory of RL and related topics in probability theory by starting with Markov chains and building up. Topics include: Markov chains, Markov decision processes, multi-armed bandit problems, dynamic programming, Monte Carlo methods, temporal difference learning. Students will develop AI algorithms using the methods from the course as part of a final project.
Background: Aside from some mathematical maturity, the only technical prerequisites are a basic understanding of probability theory (at around the level of MathStats 1) and basic programming skills (projects are required to be completed in Python and Google Collab). If you would like to take the course and are unsure about prerequisites please contact me and we can chat! (nicam@uoguelph.ca)
Other info: Course content will be delivered both by recorded lectures (which go over definitions/basic examples) as well as in-person discussions and problem solving sessions. There will also be in-class programming labs where we will implement course ideas. Other course assessments will be mostly project based.
Textbook: Reinforcement Learning: An Introduction by Richard S. Sutton and Andrew G. Barto. Available for free online from the authors at http://incompleteideas.net/book/the-book-2nd.html
Education
University of Toronto
2017 – 2020
Post-Doctoral Fellowship

New York University
2011 – 2017
PhD

University of Waterloo
2007 – 2011
BMath
Research
See my Google Scholar page for the most up to date list of my research papers. Some of my older papers are listed below.
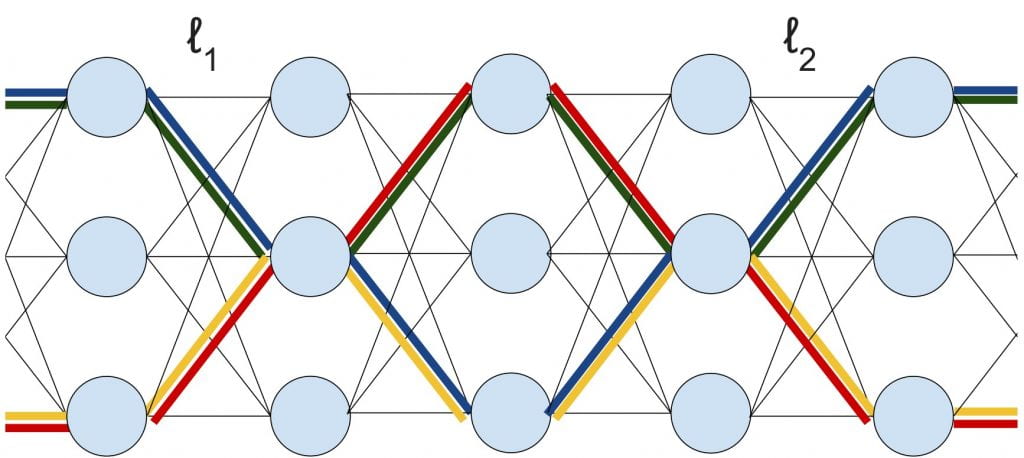
Finite Depth & Width Corrections to the Neural Tangent Kernel
(With Boris Hanan)
We prove the precise scaling, at finite depth and width, for the mean and variance of the neural tangent kernel (NTK) in a randomly initialized ReLU network. ICLR Spotlight.
. . . . .

Uniform Convergence to the Airy Line Ensemble
(With Duncan Dauvergne & Bálint Virág)
We prove a general theorem for uniform convergence to the Airy line ensemble that applies to many different last passage percolation settings
. . . . .
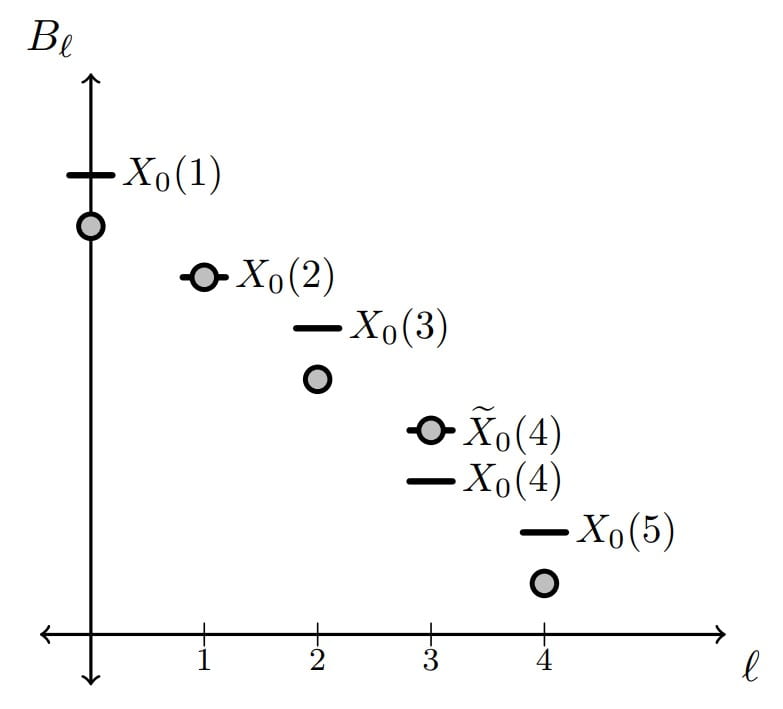
Solution of the Kolmogorov Equation for TASEP
(With Jeremy Quastel & Daniel Remenik)
We provide a direct and elementary proof that the transition probability formulas for TASEP solve the Kolmogorov backward equation. Published in Annals of Probability.
3 Blue 1 Brown Summer of Math Exposition (SoME) Contest
I like to make math videos for this annual contest organized by 3Blue1Brown!
SoME 2023
SoME 2022
SoME 2021
In summer 2021 I made a video entry for the Summer of Math Exposition contest (see https://www.3blue1brown.com/blog/some1-results and https://www.youtube.com/watch?v=F3Qixy-r_rQ for more info on the contest).
My video on the Buffon needle problem got an honorable mention! (Top 30 out of ~1200 entries)
Links to my follow up videos:
* Computer simulations in Python/Google collab: https://youtu.be/po_pmPrO2YY
* Detailed proof of proportionality: https://youtu.be/6XnkEThjQZ8
Theory of Deep Learning Notes/Videos
Notes on Infinite Depth-and-Width Limits
Notes on Feature Regression and Wide Neural Networks
Other Expository Math Notes/Videos
Notes on Fibonacci Numbers using Generating Functions and Infinite Sums
Notes on Fibonacci Numbers using Linear Algebra